Why do all my Buddies keep shilling ZFS?
This Blogpost only serves as an Introduction to ZFS, for deeper coverage refer to the sources linked at the bottom.
We all have a friend who constantly tells us about new technological features and quirks. However, we may feel hesitant to try them out ourselves.
That was exactly the case for me when a friend introduced me to ZFS.
It wasn't until later that I had the chance to experience it for myself.
Since then, I have become an advocate for changing the default file systems of my friends.
How ZFS came to be #
ZFS was initially created for OpenSolaris by Sun Microsystems, and later adapted for FreeBSD. [2]
Following Sun's acquisition by Oracle, ZFS was made proprietary, causing two-thirds of its original developers, including its creators, to resign and create OpenZFS, an open-source fork with
the goal of making ZFS available to all.[1]
In general, any non-specific reference to ZFS, except for the excerpt on its history, refers to the OpenZFS fork.
What exactly is ZFS? #
ZFS is more than only a Filesystem, it combines the functionality of a File System and a Volume manager. That means that ZFS is able to create a file system spanning across more than one drive or a pool of them. Additionally, ZFS handles any partitioning and formatting required.
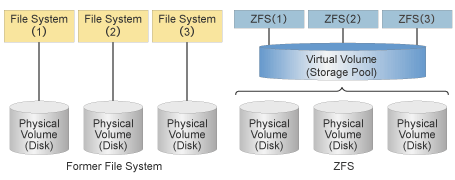
[5] - Ironically, an image from an article on proprietary ZFS is applicable since the same concepts are used.
Why isn't ZFS more popular. #
ZFS is mainly constrained by a licensing problem. The CDDL license [4], which governs ZFS, is incompatible with the Linux Kernel's licensing under the GNU GPL. The CDDL license mandates that every prior developer give their approval for a license change, which is an intricate process, particularly when some of the developers are no longer available or, at worst, deceased. Hence, it is challenging to include ZFS in Linux Distributions as the default option.[2]
Why you should use ZFS - Lets talk Features #
ZFS was developed with the following Key Points in Mind [2]:
- Protection against data corruption. Integrity checking for both data and metadata.
- Continuous integrity verification and automatic “self-healing” repair
- Data redundancy with mirroring
- Support for high storage capacities
- Space-saving with transparent compression
- Hardware-accelerated native encryption
- Efficient storage with snapshots and copy-on-write clones
- Efficient local or remote replication
The key points of the vast array of features in ZFS will be discussed in the next section. I will focus on what I consider to be the most important ones and keep the description relatively high level. My favourite section is undoubtedly ZFS send - prepare to have your mind bent.
Caching #
ZFS employs both write and read caching.
The primary form of write caching is the Transaction File System (TFS).
When data is stored in the file system, it is first cached in the RAM and then written to the disk in fixed intervals in the form of Transaction Groups (TXG).
This approach enhances performance, especially for spinning disks, but may result in dropped transactions in the event of power outages.
For Read Caching, there are two essential core concepts: ARC (Adaptive Replacement Caches) in the form of ARC and L2ARC.
ARC caches frequently read data in the RAM and drops it when the RAM is required for other programs, while L2ARC enables ZFS to use PCIE-based SSDs as faster cache drives for often-requested files.
It's important to note that ARC caching is enabled and handled without any further configuration and can potentially improve access speeds dramatically.[6]
Copy on Write and Snapshots #
ZFS utilises a copy-on-write method to store data.
This approach stores data in a way that enables modifications to be made without overwriting the original data.
Whenever data changes are made using copy-on-write, a duplicate of the earlier version is generated and the modifications are stored in a new location.
This guarantees that the original data is preserved, even if the changes are later undone or the data is corrupted.
This functionality is mandatory for utilising Snapshots, another key feature of ZFS.
ZFS snapshots are immutable duplicates of a file system that are created at a specific moment in time.
They allow for the creation of instantaneous copies of a file system.
These copies can be used for data backup, recovery from unintentional changes, or software testing.
Copy-on-write is used to create snapshots, meaning they don’t use up additional disk space until the referenced data is modified.[7]
Deduplication, Compression #
ZFS provides a block-level deduplication feature that ensures storage efficiency by storing the same data only once. If there are multiple files with identical data or any other duplicated data within the storage pool, ZFS will only store one copy of it. ZFS maintains a Deduplication Table (DDT), which is a mapping table that connects files and pool data to their corresponding storage blocks that contain their data.[8] ZFS has the ability to compress files using various algorithms, such as LZ4. This allows for more data to be stored in the same space, which is particularly useful when storing large amounts of easily compressible data. However, this feature comes at a cost, as it requires CPU resources to compress and decompress files on the fly. As a result, it may not be suitable for all use cases. [9]
Native Encryption #
To explain native encryption, I must first introduce the concept of datasets.
ZFS uses pools as described above, while the actual data (FS, snapshots, etc.) is stored in datasets, which are themselves stored in pools[10].
In contrast to classical full disk encryption, ZFS allows encryption on a per dataset basis, which makes it possible to mix encrypted and unencrypted datasets in a single pool.
This also allows booting from an unencrypted dataset and unlocking the encrypted dataset after the boot process (e.g. via SSH in the case of a server).
Additionally, ZFS Encryption implementation enables carrying out maintenance operations, such as integrity checks, scrubbing, and resilvering, while the dataset remains locked.
This is particularly useful when we look at ZFS send in the next chapter.
However, this implementation exposes the file's metadata, including the dataset's name, size, usage, and properties.
Apart from that, ZFS Encryption relies on standard encryption methods such as AES-256, and can be unlocked with a passphrase.
ZFS send #
This function at first blew me away because it is so powerful and yet so ingenious. ZFS enables you to send Snapshots of Datasets over the Internet. This means you can send a full snapshot of your encrypted dataset to another machine across the internet. Once you accept the Snapshot via ZFS receive, it will be attached to a pool specified.[12] The truly remarkable aspect is the remote machine's ability to verify data integrity, repair the dataset, and receive successive incremental snapshots while keeping the dataset encrypted and locked.[2] This, in turn, enables transferring your machine's backup to an untrusted third party.
Integrity Check & Repair #
ZFS is a file system known for prioritising data integrity protection. It protects against various sources of data corruption, such as power problems, disk errors and more. ZFS uses checksums and a Merkle tree structure to validate data at multiple levels in the file system hierarchy. When data is accessed, its checksum is compared to the expected value, and if they don't match, ZFS can recover the data from redundant copies, if available. Consistency of data held in memory, such as cached data in the ARC, is not checked by default because ZFS expects ECC.[2]
Pooling and Raid Management #
As mentioned above, in addition to being a FS, ZFS is also a volume manager. ZFS implements volume management using pools. ZFS pools are storage configurations that group physical drives (such as hard disks or SSDs) into a single unit for efficient data management. They use a technology called RAID-Z to provide data redundancy and protection against drive failures. Raid-Z is ZFS's own raid format based on the concepts of Raid 5.[2] One of the key benefits of ZFS pooling is that the partitioning and formatting of the storage is completely handled by ZFS once the pool and raid configuration have been defined. This allows the user to add new drives to the pool while it is running and being used.
In addition to the mentioned features, ZFS also supports various others, such as Unix-permission based native SMB shares for Datasets.
Things to keep in Mind - Counterarguments #
Since ZFS relies on RAM for caching files and metadata and during parity checking, bit flips would be disastrous.
ECC RAM is highly recommended, although it is not a strict requirement (Intel's artificially fabricated lack of ECC RAM in the consumer space may be the topic of another blog post).
Additionally, ZFS is designed to be a zero-maintenance file system.
However, to use, maintain and repair it properly, it is necessary to have a good understanding of its core concepts.
Due to the restrictive licensing, it is unlikely that ZFS will be included in your preferred distribution of choice.
Manual configuration of the Installation Image is probably required for a ZFS root based System.
If you really want to use Windows or macOS there is definitely no hope for you - and no ZFS. [2]
This article has grown much larger than I originally anticipated, but I'm happy to share the mystical world of ZFS with you.
[1] - OpenZFS Gentoo Wiki
[2] - OpenZFS Wiki
[3] - OpenZFS Github
[4] - Common Development and Distribution License Wikipedia
[5] - Solaris ZFS of Solaris™ 10 Operating System function Fujitsu
[6] - ZFS Caching 45 Drives
[7] - ZFS Copy-on-write & Snapshots open-e
[8] - ZFS Deduplication TrueNAS
[9] - ZFS basics: enable or disable compression UnixTutorial
[10] - ZFS auf Linux/ Dataset DE Wikibooks
[11] - OpenZFS Native Encryption klara inc.
[12] - ZFS send/recv full snapshot - Unix Stackexchange